How can I clear the Microsoft exam 70-534 dumps on Microsoft Certification? “Architecting Microsoft Azure Solutions” is the name of Microsoft 70-534 exam dumps which covers all the knowledge points of the real Microsoft exam. Money back guarantee free Microsoft Azure 70-534 dumps practice test exam certification youtube training.
Pass4itsure Microsoft 70-534 dumps exam questions answers are updated (249 Q&As) are verified by experts. The associated certifications of 70-534 dumps is Microsoft Specialist Microsoft Azure. Passing the Microsoft https://www.pass4itsure.com/70-534.html dumps certification exam has never been easier, but with use of our preparation material, it is simple and easy.
Exam Code: 70-534
Exam Name: Architecting Microsoft Azure Solutions
Updated: Sep 16, 2017
Q&As: 249
[Free Microsoft 70-534 Dumps&PDF From Google Drive]: https://drive.google.com/open?id=0BwxjZr-ZDwwWdmxvVW43RmxVM2M
[Free Microsoft 70-695 Dumps&PDF From Google Drive]: https://drive.google.com/open?id=0BwxjZr-ZDwwWYS1lM3BQOC1zaFU
Design Azure Resource Manager (ARM) networking (5 – 10%)
- Design Azure virtual networks – Leverage Azure networking services: implement load balancing using Azure Load Balancer and Azure Traffic Manager; define DNS, DHCP, and IP addressing configuration; define static IP reservations; apply Network Security Groups (NSGs) and User Defined Routes (UDRs); deploy Microsoft 70-534 Dumps Azure Application Gateway
- Describe Azure VPN and ExpressRoute architecture and design – Describe Azure P2S and S2S VPN; leverage Azure VPN and ExpressRoute in network architecture

Pass4itsure Latest and Most Accurate Microsoft 70-534 Dumps Exam Q&As:
QUESTION 1
You need to design the system that alerts project managers to data changes in the contractor informaton
app.
Which service should you use?
A. Azure Mobile Service
B. Azure Service Bus Message Queueing
C. Azure Queue Messaging
D. Azure Notfcaton Hub
70-534 exam Correct Answer: C
QUESTION 2
You need to prepare the implementaton of 70-534 dumps data storage for the contractor informaton app.
What should you?
A. Create a storage account and implement multple data parttons.
B. Create a Cloud Service and a Mobile Service. Implement Entty Group transactons.
C. Create a Cloud Service and a Deployment group. Implement Entty Group transactons.
D. Create a Deployment group and a Mobile Service. Implement multple data parttons.
Correct Answer: B
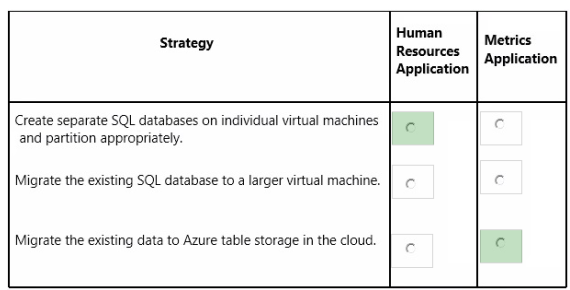
QUESTION 3
HOTSPOT
You need to design a data storage strategy for each applicaton.
In the table below, identfy the strategy that you should use for each applicaton. Make only one selecton in
each column.
Hot Area:

Correct Answer:
QUESTION 4
You need to recommend a soluton for publishing one of the company websites to Azure and confguring it
for remote debugging.
Which two actons should you perform? Each correct answer presents part of the soluton.
A. From Visual Studio, atach the debugger to the soluton.
B. Set the applicaton logging level to Verbose and enable logging.
C. Set the Web Server logging level to Informaton and enable logging.
D. Set the Web Server logging level to Verbose and enable logging.
E. From Visual Studio, confgure the site to enable Debugger Ataching and then publish the site.
Correct Answer: AD
QUESTION NO: 5
Which three distcp features can you utilize on a Hadoop cluster?
A. Use distcp to copy files only between two clusters or more. You cannot use distcp to copy data
between directories inside the same cluster.
B. Use distcp to copy HBase table files.
C. Use distcp to copy physical blocks from the source to the target destination in your cluster.
D. Use distcp to copy data between directories inside the same cluster.
E. Use distcp to run an internal MapReduce job to copy files.
70-534 pdf Answer: B,D,E
DistCp (distributed copy) is a tool used for large inter/intra-cluster copying. It uses
Map/Reduce to effect its distribution, error handling and recovery, and reporting. It expands a list
of files and directories into input to map tasks, each of which will copy a partition of the files
specified in the source list. Its Map/Reduce pedigree has endowed it with some quirks in both its
semantics and execution.
Reference: Hadoop DistCp Guide
QUESTION NO: 6
How does HDFS Federation help HDFS Scale horizontally?
A. HDFS Federation improves the resiliency of HDFS in the face of network issues by removing
the NameNode as a single-point-of-failure.
B. HDFS Federation allows the Standby NameNode to automatically resume the services of an
active NameNode.
C. HDFS Federation provides cross-data center (non-local) support for HDFS, allowing a cluster
administrator to split the Block Storage outside the local cluster.
D. HDFS Federation reduces the load on any single NameNode by using the multiple,
independent NameNode to manage individual pars of the filesystem namespace.
Answer: D
HDFS FederationIn order to scale the name service horizontally, federation uses
multiple independent Namenodes/Namespaces. The Namenodes are federated, that is, the
Namenodes are independent and don’t require 70-534 vce coordination with each other. The datanodes are
used as common storage for blocks by all the Namenodes. Each datanode registers with all the
Namenodes in the cluster. Datanodes send periodic heartbeats and block reports and handles
commands from the Namenodes.Reference: Apache Hadoop 2.0.2-alpha
QUESTION NO: 7
Choose which best describe a Hadoop cluster’s block size storage parameters once you set the
HDFS default block size to 64MB?
A. The block size of files in the cluster can be determined as the block is written.
B. The block size of files in the Cluster will all be multiples of 64MB.
C. The block size of files in the duster will all at least be 64MB.
D. The block size of files in the cluster will all be the exactly 64MB.
70-534 exam Answer: D
Note: What is HDFS Block size? How is it different from traditional file system block
size?In HDFS data is split into blocks and distributed across multiple nodes in the cluster. Each block is
typically 64Mb or 128Mb in size. Each block is replicated multiple times. Default is toreplicate each
block three times. Replicas are stored on different nodes. HDFS utilizes the local file system to
store each HDFS block as a separate file. HDFS Block size can not be compared with the
traditional file system block size.
QUESTION NO: 8
Which MapReduce daemon instantiates user code, and executes map and reduce tasks on a
cluster running MapReduce v1 (MRv1)?
A. NameNode
B. DataNode
C. JobTracker
D. TaskTracker
E. ResourceManager
F. ApplicationMaster
G. NodeManager
Answer: D
A TaskTracker is a slave node daemon in the cluster that accepts tasks (Map,
Reduce and Shuffle operations) from a JobTracker. There is only One Task Tracker process run
on any hadoop slave node. Task Tracker runs on its own JVM process. Every TaskTracker is
configured with a set ofslots, these indicate the number of tasks that it can accept. The
TaskTracker starts a separate JVM processes to do the actual work (called as Task Instance) this
is to ensure that process failure does not take down the task tracker. The TaskTracker monitors
these task instances, capturing the output and exit 70-534 dumps codes. When the Task instances finish,
successfully or not, the task tracker notifies the JobTracker. The TaskTrackers also send out
heartbeat messages to the JobTracker, usually every few minutes, to reassure the JobTracker
thatit is still alive. Thesemessage also inform the JobTracker of the number of available slots, so
the JobTracker can stay up to date with where in the cluster work can be delegated.
Note: How many Daemon processes run on a Hadoop system?
Hadoop is comprised of five separate daemons. Each of these daemon run in its own JVM.
Following 3 Daemons run on Masternodes NameNode – This daemon stores and maintains the
metadata for HDFS. Secondary NameNode – Performs housekeeping functions for the NameNode.
JobTracker – Manages MapReduce jobs, distributes individual tasks to machines running the Task
Tracker. Following 2 Daemons run on each Slave nodes DataNode – Stores actual HDFS data blocks.
TaskTracker – Responsible for instantiating and monitoring individual Map and Reduce tasks.
Reference: 24 Interview Questions & Answers for Hadoop MapReduce developers, What is a
Task Tracker in Hadoop? How many instances of TaskTracker run on a Hadoop Cluster.
QUESTION NO: 9
What two processes must you do if you are running a Hadoop cluster with a single NameNode
and six DataNodes, and you want to change a configuration parameter so that it affects all six
DataNodes.
A. You must restart the NameNode daemon to apply the changes to the cluster
B. You must restart all six DataNode daemons to apply the changes to the cluster.
C. You don’t need to restart any daemon, as they will pick up changes automatically.
D. You must modify the configuration files on each of the six DataNode machines.
E. You must modify the configuration files on only one of the DataNode machine
F. You must modify the configuration files on the NameNode only. DataNodes read their
configuration from the master nodes.
70-534 pdf Answer: A,F
Note:Typically one machine in the cluster is designated as the NameNode and
another machine the as JobTracker, exclusively. These are the masters. The rest ofthe machines
in the cluster actas both DataNode and TaskTracker. These are the slaves.
Microsoft exams are updated on regular basis to ensure our members success in 70-534 dumps real exam, Pass4itsure members get access to download section where https://www.pass4itsure.com/70-534.html dumps certification test up-to-date document can be downloaded and viewed.